Tensorboard基础应用
一、生成流程图
1. 给参数命名
with tf.name_scope('Weights'):
#指定命名空间,对于单个参数,也有命名的作用
Weights = tf.Variable(tf.random_normal([in_size, out_size]), name='weight')
#传入name='name'来命名,这里的名字是唯一的,如果重复了,tf会自动在名字末尾加数字后缀
2. 生成日志
sess = tf.Session()
#在定义完session之后,规定路径,输出日志,这里输入的路径是脚本所在目录的相对路径
writer = tf.summary.FileWriter("logs/", sess.graph)
3. 指定日志路径
在控制台执行命令:
user$ tensorboard --logdir="Log Path"
#这里的"Log Path"要替换为日志目录的绝对路径
TensorBoard 1.11.0 at http://127.0.0.1:6006 (Press CTRL+C to quit)
#浏览器打开该链接即可看到Tensorboard生成的流程图
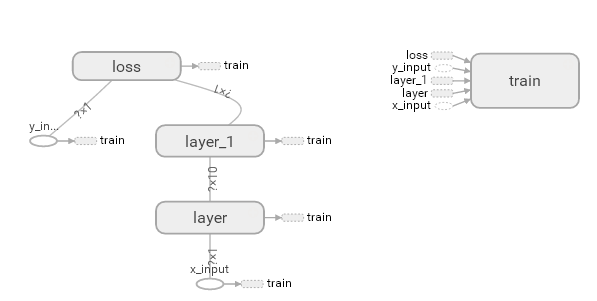
二、训练过程可视化
利用Tensorboard,可以通过图表来观察统计训练过程中参数的变化情况。下面的例子适用于观察Weights和Biases的变化
1. 为参数设置历史变化图表
- 观察Weights和Biases的变化
with tf.name_scope('Layer'):
#1 参数的初始化
with tf.name_scope('Weights'):
Weights = tf.Variable(tf.random_normal([in_size, out_size]), name='weight')
#生成初始参数时,最好用一个随机变量,这里的权值为一个in_size行,out_size列的随机变量矩阵
tf.summary.histogram(Weights.name, Weights)
#生成Weights的历史变化图表
# tf.histogram_summary(layer_name+'/weights',Weights) # tensorflow 0.12 以下版的
with tf.name_scope('Biases'):
Biases = tf.Variable(tf.zeros([1, out_size]) + 0.1, name='bias')
#机器学习中,偏置的推荐值不为0,因此这里是在0向量的基础上增加了0.1
tf.summary.histogram(tf.name_scope.name+'/Biases', Biases)
- 观察Loss的变化
with tf.name_scope('Loss'):
loss = tf.reduce_mean(tf.reduce_sum(tf.square(ys-prediction), axis=1))
tf.summary.scalar('loss', loss) # tensorflow >= 0.12
2. 将图表合并打包
init = tf.global_variables_initializer()
#使用变量时,需要对它们进行初始化,这一函数可以一次性初始化所有变量
sess = tf.Session()
writer = tf.summary.FileWriter("logs/", sess.graph)
# 进行图表合并
# merged= tf.merge_all_summaries() # tensorflow < 0.12
merged = tf.summary.merge_all() # tensorflow >= 0.12
sess.run(init)
#定义Session,并进行变量的初始化工作
3. 在图表中写入数据
merged也是需要run才能生效的,这里我们规定训练50次记录一次数据
for i in range(1000):
sess.run(train_step, feed_dict={xs:x_data, ys:y_data})
if i%50 == 0:
rs = sess.run(merged,feed_dict={xs:x_data,ys:y_data})
writer.add_summary(rs, i)
打开Tensorboard就能看到记录下数据的图表啦
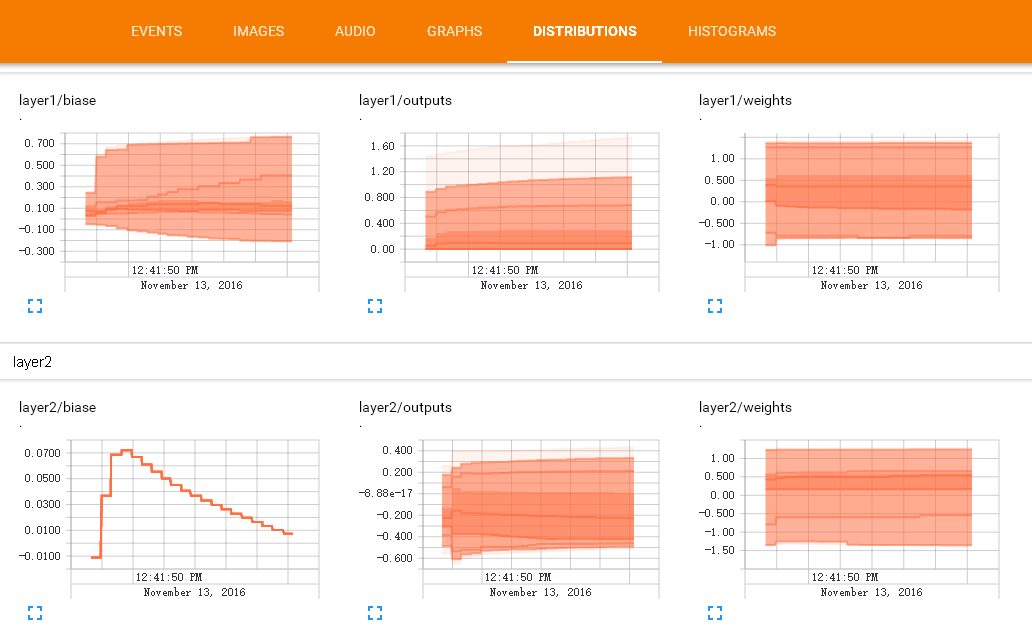
学习笔记(一)~(三)部分源码
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
# 一、定义一个添加神经层的函数,有四个参数:输入值、输入值的size、输出的size和激励函数,此处设定默认激励函数为None
def add_layer(inputs, in_size, out_size, activation_function=None):
with tf.name_scope('Layer'):
#1 参数的初始化
with tf.name_scope('Weights'):
Weights = tf.Variable(tf.random_normal([in_size, out_size]), name='weight')
#生成初始参数时,最好用一个随机变量,这里的权值为一个in_size行,out_size列的随机变量矩阵
tf.summary.histogram(Weights.name, Weights)
with tf.name_scope('Biases'):
Biases = tf.Variable(tf.zeros([1, out_size]) + 0.1, name='bias')
#机器学习中,偏置的推荐值不为0,因此这里是在0向量的基础上增加了0.1
tf.summary.histogram(Biases.name, Biases)
#2 神经层的输出
with tf.name_scope('Wx_plus_b'):
Wx_plus_b = tf.add(tf.matmul(inputs, Weights), Biases)
#定义神经网络的默认值,matmul为矩阵乘法函数
if activation_function is None:
outputs = Wx_plus_b
else:
outputs = activation_function(Wx_plus_b)
#如果激活函数为None,那么outputs = Wx_plus_b,否则outputs为激活函数对Wx_plus_b的响应值
tf.summary.histogram(outputs.name + '/Outputs', outputs)
return outputs
# 二、导入数据
#1 构造所需的数据
x_data = np.linspace(-1,1,300,dtype=np.float32)[:, np.newaxis]
#np.newaxis的功能是插入新的维度
#https://blog.csdn.net/mameng1/article/details/54599306
noise = np.random.normal(0,0.05,x_data.shape)
#x_data.shape返回数组的大小,如(2,3)就是2行3列的数组
y_data = np.square(x_data) - 0.5 + noise
#为y值添加一点噪声,更接近真实情况
#2 定义神经网络的输入
with tf.name_scope('Inputs'):
xs = tf.placeholder(tf.float32, [None, 1], name="x_input")
ys = tf.placeholder(tf.float32, [None, 1], name="y_input")
#利用占位符placeholder定义所需的输入,None表示不限定输入的数量,1为输入的行数(或特征的数量,一般的,一行是同一种特征的数据)
#name是标示这个placeholder的唯一名称,也可以不做定义
# 三、搭建网络
#本例中,我们将搭建:输入层1个,隐藏层10个、输出层1个的神经网络
l1 = add_layer(xs, 1, 10, activation_function=tf.nn.relu)
#l1层有1个输入,10个输出,激励函数为tf自带的tf.nn.relu
prediction = add_layer(l1, 10, 1, activation_function=None)
#输出层predicion的输入为l1的输出,即10个输入,1个输出,激励函数为None
with tf.name_scope('Loss'):
loss = tf.reduce_mean(tf.reduce_sum(tf.square(ys-prediction), axis=1))
#tf.reduce_mean是通过求平均值对input_tensor降维的函数,axis规定的是降维的方向
#https://blog.csdn.net/yjk13703623757/article/details/77284692
#定义损失函数,这里采用了对(ys-prediction输出值)的平方求和后,再取平均值的办法
tf.summary.scalar('loss', loss) # tensorflow >= 0.12
with tf.name_scope('Train'):
train_step = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
#定义tf要如何学习,这里采用了梯度下降法,选取学习效率为0.1,目标为最小化误差loss
init = tf.global_variables_initializer()
#使用变量时,需要对它们进行初始化,这一函数可以一次性初始化所有变量
sess = tf.Session()
writer = tf.summary.FileWriter("logs/", sess.graph)
# merged= tf.merge_all_summaries() # tensorflow < 0.12
merged = tf.summary.merge_all() # tensorflow >= 0.12
sess.run(init)
#定义Session,并进行变量的初始化工作
# 三.1、绘图
#plot the real data
fig = plt.figure()
ax = fig.add_subplot(1,1,1)
ax.scatter(x_data, y_data)
plt.ion() #用于连续绘图
#plt.show() #调用show时会暂停函数的运行,或者传入参数block=False
# 四、学习
#本例的学习边界为进行1000次学习,学习的内容为train_step
#利用feed_dict传入放在placehodler中的数据
for i in range(1000):
#training,这一步要传入数据集
sess.run(train_step, feed_dict={xs: x_data, ys: y_data})
#每50步输出一次loss的值
if i % 50 == 0:
#print(sess.run(loss, feed_dict={xs: x_data, ys: y_data}))
try:
ax.lines.remove(lines[0]) #try去除上一步绘制出来的曲线
except Exception:
pass
prediction_value = sess.run(prediction, feed_dict={xs: x_data})
#获取prediciton的值,即神经网络的输出
lines = ax.plot(x_data, prediction_value, 'r-', lw=5)
#绘制曲线,参数为横坐标,纵坐标,线的颜色和类型,宽度
#plt.pause(0.1)
rs = sess.run(merged, feed_dict={xs: x_data, ys: y_data})
writer.add_summary(rs, i)
sess.close()
#释放资源
